400-618-1990


新闻中心
一种基于机器学习的自动文档标签图谱技术
【工业软件学习营】第一期第3讲
【工业软件学习营】总第53讲,于2021年3月19日如期举行,本期讲师是瑞风协同技术总监,具有20余年软件开发和架构设计经验,参与多个领域的设计仿真平台、材料库、知识库系统建设,重点研究方向为大数据技术和人工智能技术,专注于文本挖掘技术、自然语言处理技术在知识库自动构建、知识自动分类、知识智能推送、知识关联挖掘、知识图谱方面的应用研究。
本期课程重点分为以下四个方面:知识图谱技术发展趋势、基于机器学习的标签图谱技术思路、关键技术分析、典型应用案例分享。
一、知识图谱技术发展趋势
1. 知识图谱
(1)定义
知识图谱:是一种规模非常大的语义网络系统,是海量文本知识挖掘最常见的手段之一。知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,一般用三元组表示。知识图谱亦可被看作是一张巨大的图,节点表示实体或概念,而边则由属性或关系构成。

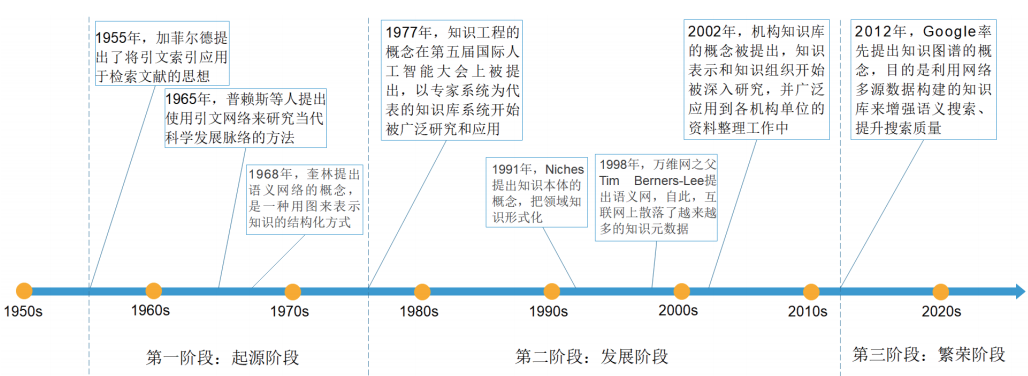
(2)发展历程
知识图谱的发展分为起源、发展、繁荣三个阶段。
(3)应用
目前,知识图谱在金融、医疗、教育、司法等多个行业领域广泛应用。
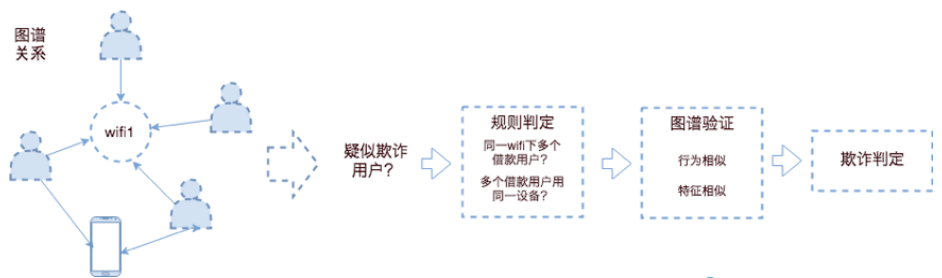
• 金融行业:反洗钱、反欺诈等
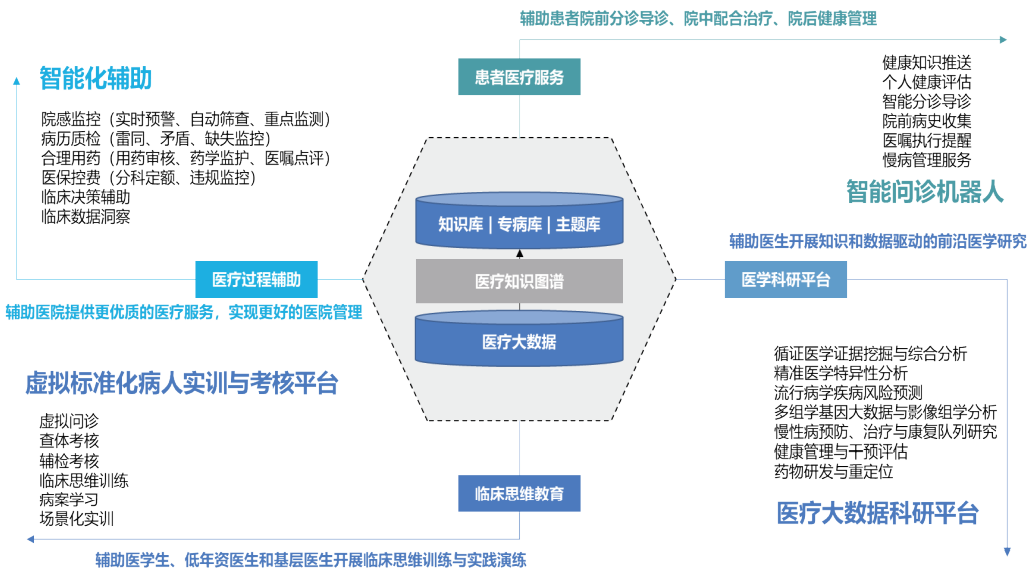
• 医疗行业
• 教育行业
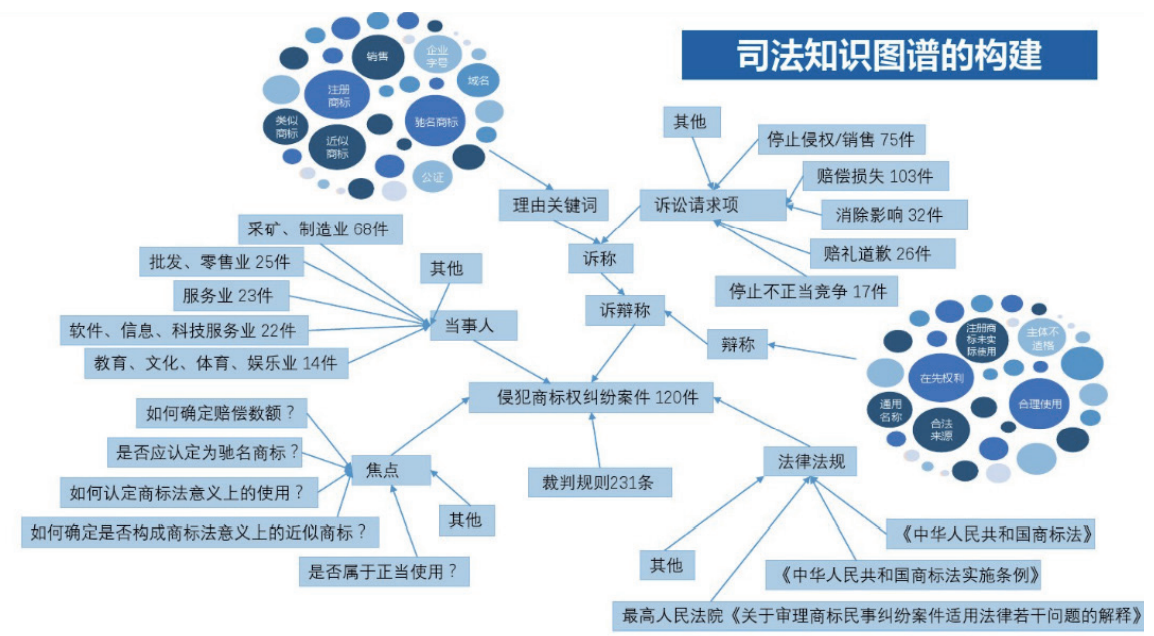
• 司法:知识图谱在司法中能解决证据索引、类案推送、结果预判、证据分析、文书生成和智慧调解
(4)重要作用
知识图谱具有获取、表示和处理知识的能力,是人类心智区别于其它物种心智的重要特征,且已成为推动机器基于人类知识来获取认知能力的重要途径,并将逐渐成为未来智能社会的重要生产资料。
知识图谱是人工智能的基石,包括感知层与认知层。知识图谱推动人工智能的应用,是强人工智能发展的核心驱动力之一。
(5)知识图谱的特点
• 特点:
√ 适用范围:面向文本知识和数据
√ 数据方面:要求具备一定的数据量
√ 知识内容:对知识的宽度、深度有要求,视具体业务情况
√ 要求数据标注:机器学习的前提,越多越好
√ 需要业务专家评估结果的准确性
√ 通用性较差:不同行业效果差异很大
√ 技术复杂:涉及业务、信息、网络、人工智能、算法、图形和大数据等多个方面
2. 知识图谱面临多方面的挑战
(1)数据方面的挑战:多源数据的歧义多、噪声大,数据关联性不明确
(2)算法挑战:现有算法知识抽取准确性、算法性能和算法可解释性的挑战(各行业不一样)
(3)基础知识库的挑战:知识库融合、垂直领域知识库构建、基础知识库不开放
(4)开发工具的挑战:全生命周期平台的缺失、算法工具专家间人机协同需要提升、基于文本的知识图谱构建工具性能弱、跨语言语系的挑战、知识图谱中间件缺乏
(5)隐私、安全方面的挑战
(6)测试认证方面的挑战
(7)商业模式与人才相关的挑战
(8)标准化方面的挑战
3. 工业领域文档知识特点
知识图谱在通用领域得到广泛的应用与发展,但在工业领域的应用却不是很多,这与工业领域的行业特点、专业性、保密性和复杂性有关。
(1)原始文档知识数据庞大、格式繁多:知识获取很复杂、技术难度高、成本高、时间长
(2)年增长速度很快、存储分散
(3)专业性太强:与具体的场景关联很强
(4)公开的工业知识库很少
(5)保密性强:知识传播、共享有限制
(6)专业学科多,知识应用复杂:通用性不强,成本高
4. 工业领域知识图谱面临的问题
与传统通用领域不同,工业领域的知识图谱在知识获取、知识应用方面存在较大的困难,总结起来主要有以下几点:
• 工业知识获取技术难度高、投入大、周期长
• 小批量、小样本下的知识图谱如何生成
• 知识图谱的准确度问题
• 与结构化数据的知识融合问题
• 缺乏标准化的知识图谱平台:任意扩展算法、语种、专业学科
• 自主可控问题
二、基于机器学习的标签图谱技术思路
1. 标签的定义与意义
(1)标签定义:是知识内容高度抽象、高度概括的具现化,是知识某个维度的特征。它具有丰富的含义和内涵,内容简单、明了。
(2)标签作用:分类、快速查找、快速了解、用户画像、产品画像……
(3)标签在工业领域中的意义:
• 具备常规标签功效和能力
• 专业性:专业术语、词汇、主题……
• 是工业知识图谱基于知识运维模式的重要方法之一:标签可以认为是关键词、主题、事件
2. 标签应用
标签应用:非常广泛,比如知识分类、信息关联、用户画像、产品画像、数据统计挖掘等。以客户管理为例,客户管理是制定六大目标的相关标签体系,可以实现精确客户营销,产生最大客户价值。
3. 标签体系构建方法
(1)三大原则:
• 放弃大而全的框架,以业务场景倒推标签需求
• 标签生成自动化,解决效率和沟通成本
• 有效的标签管理机制
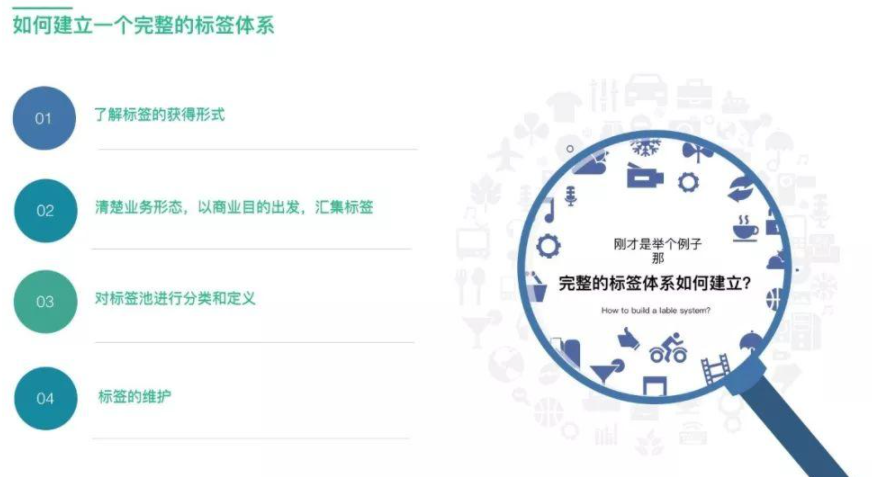
(2)建立一个完整的标签体系需要注重四点:
4. 标签示例
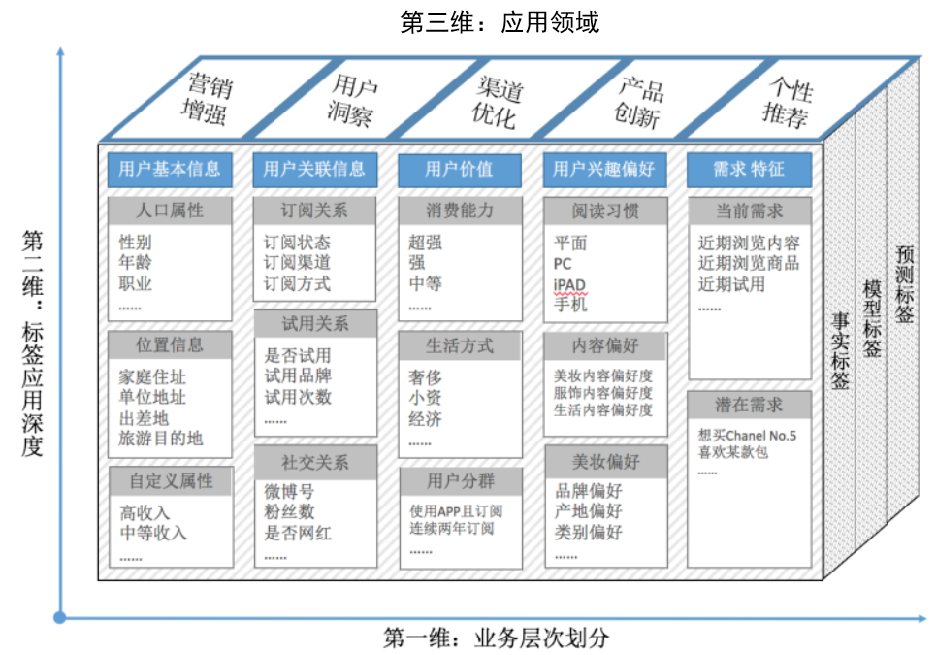
电商标签体系示例
知识三维标签体系示例
5. 基于标签图谱的技术思路
(1)思路重点:标签代替实体
(2)影响准确度的因素:
• 预处理结果质量
• 标签实体识别
• 关系抽取
• AI算法优化
• 业务协同程度
(3)基于知识运维的知识图谱特点:原始数据少、通过迭代逐步丰富数据、通过迭代校正图谱中的错误、逐步把专家头脑中的知识挖掘出来,特别注重人机协同。
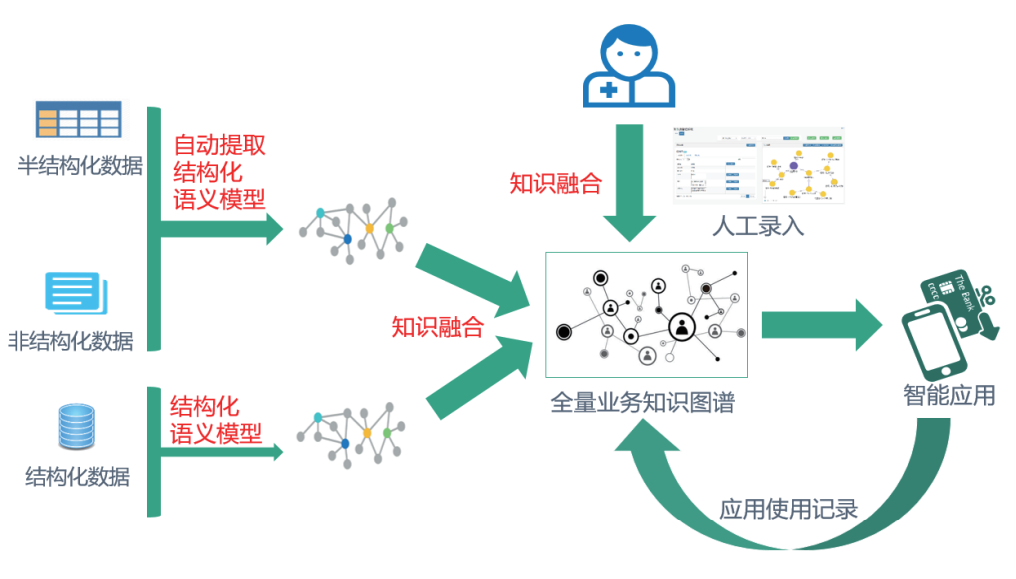
三、关键技术分析
1. 智能标签技术
(1)技术要点:基于人工智能算法,从单个文档里提取若干个内容特征词作为文档的内容标签
(2)标签目的:为下一步内容标签实体处理、标签实体关系和标签应用提取做准备
(3)专业要求:
• 提供专业词汇库、术语库、近义词/同义词库可以提高专业性(必填项)
• 通过预设标签和编码,可以规范标签名称,缩小标签范围
• 通过预设关联词之间的关系和权重,可以精确语义理解,消除二义性
• 通过人工标注,可以提高准确性(可选项)
• 在标签使用过程中,可以人工纠错(类似人工标注,小样本知识图谱常用的手段)
2. 标签关系抽取技术
• 常规知识图谱要素:实体、关系、方向
• 标签知识图谱要素:与常规知识图谱类似
√ 标签=实体
√ 关系:按常规方法抽取
√ 方向:按常规方法抽取
√ 标签图谱类似关键词图谱、主题图谱
√ 自动化:辅以人工标注(工作量小、简单)
3. 标签图谱存储与可视化技术
• 图谱结构:三元关系,即对象A-关系-对象B
• 图谱存储:RDBMS数据库或图数据库
• 图谱检索:以标签为基础,也可以是一段文字
• 可视化:ECHART图表等,与具体的图谱数据没有直接关系,扩展能力强
四、典型应用案例分享
1. 基于试验知识文档的标签知识图谱需求
• 背景:
在某试验单位试验设计师的工作电脑上,存放着多年与试验相关的参考文档。虽然已对其进行初步分类,整理成多个分件夹和子文件夹,但有些文件夹下文档比较多,而有些文件夹下仅有一个文档,同时每年都在不停地更新,这会造成使用时的不便,我们可以将其归纳为以下几点主要问题:
√ 麻烦:每次查找资料时不能一下全部找到,需要按文件夹逐层往下找
√ 效率低:每次查看文档时,必须要打开文档大概看一遍,才知道里面是否有想要的内容
√ 专业性不精确:与试验相关的资料越来越多,专业性越来越强,文件夹命名已不能体现文档的内容
√ 信息孤岛现象严重:想要的内容分散在不同的文档里,不能在多个文档中快速找到想要的内容
• 需求:提供一个工具或方法,能快速解决上述问题
2. 试验参考文档分析
(1)源文档分析
• 文档总数:3500多篇
• 目录个数:82个
• 二三级目录有不少
• 多种文件格式:WORD、PDF、TXT
• 涉及专业比较宽:试验、大数据、云计算、试验件、试验方案和试验报告等
• 试验相关的文献占一半左右
(2)试验类文档分析
• 业务类:31个目录,647个文献
• 数据类:11个目录,982个文献
• 文档分布不均:有的多,有的少
(3)技术思路
• 总体思路:采用基于机器学习的自动文档标签图谱技术来解决
• 理由:
√ 文档覆盖面比较宽,但细分类的文档数量太少,最少的仅有一篇文档,不适合大规模知识图谱技术
√ 文档在不断更新,但更新的数量不会很多
√ 使用者是业务专家,有足够的资历、能力来协助工人智能自动打标签、生成知识图谱
√ 使用者可以随时纠正图谱中的错误
• 主要步骤:
√ 文本预处理
√ 知识文档语义化
√ 智能自动打标签
√ 校正智能标签准确性
√ 自动标签图谱
√ 校正标签图谱的准确性
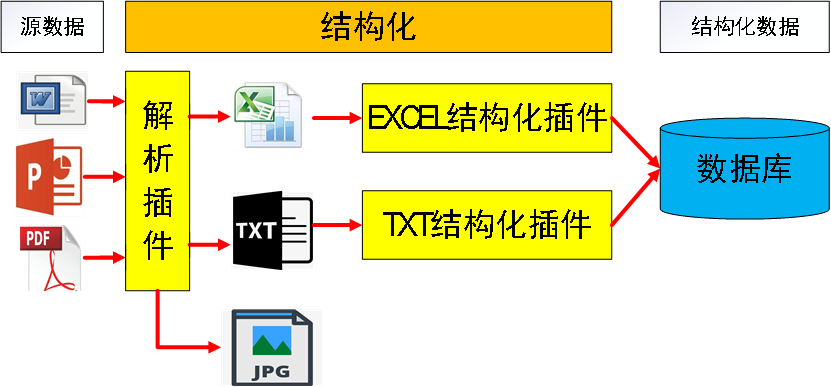
• 预处理要点与结果展示:
√ 必须把文档里的图片、表格单独抽取出来做特殊处理
√ 注意论文竖排版面格式
√ 表格里的数据需要单独处理
3. 试验知识文档智能标签
智能自动标签:预设标准化的试验标签与编码,由人工智能根据文档内容来决定对标预设的标签,通过多种标签提取算法综合分析来决定合适的标签(默认前10个)。在试验专业术语、词汇、同近义词辅助下,准确率高达90%以上。
4. 试验标签知识图谱
(1)图谱生成
基于中文语法、词性和句子成分,采用先进、成熟的标签实体关系抽取算法来抽取关系,标签实体构成图谱“三元”关系。
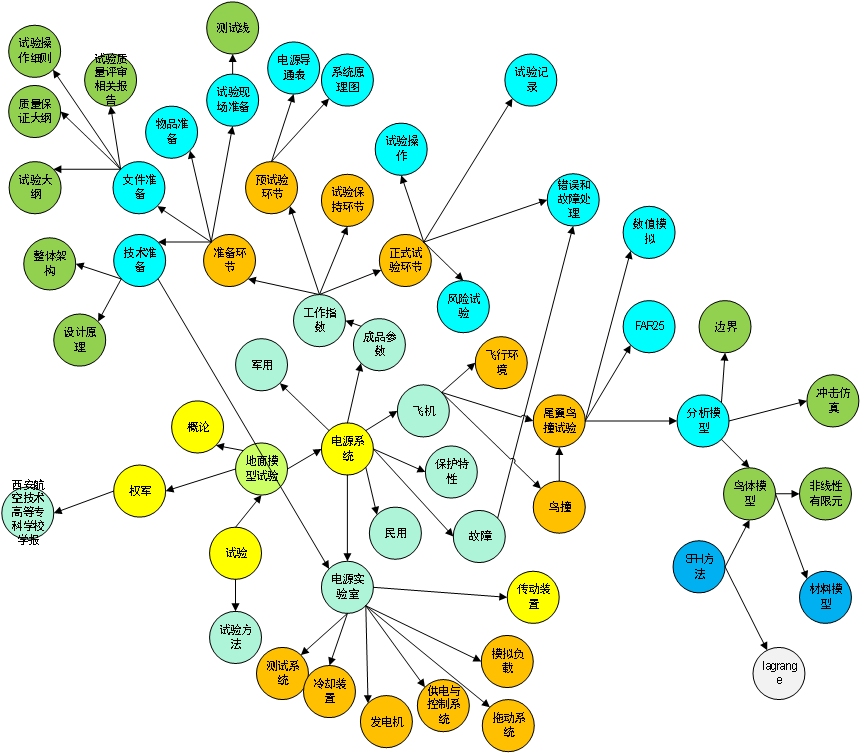
地面模型试验图谱示例
(2)准确性提升
• 试验数据方面:
√ 试验辅助词库:专业术语、同义词、近义词、关联词
√ 二义性消除:通过关联词权重规则
√ 扩大关联词范围:人工给出小部分,大部分由人工智能给出,然后由人工确定是否选用为关联词
√ 通过专业工具对两竖排排版的文献进行单独处理
• 技术方面:
√ 选用多种算法综合比较分析,择优选择标签并排序
√ 辅助人工标注、学习,提升准确性
如果您对我们的课程感兴趣,欢迎扫描下方二维码进行听课!

文章部分图片来源于网络

新闻中心